以前、「15分おきに楽天ランキングのキャプチャを自動で取る方法」という記事を書きました。
上記方法でもキャプチャできるのですが、下記のことからpythonでキャプチャ取るように修正しました。
- サイズ調整がうまくできていない
- 文字のジャギーが目立つ
pythonとseleniumのインストール
今回は、Windowsでの方法のみ書きます。
Macはもう手元にないので、今後のこのブログはWindowsのみの記述になります。
pythonのインストールは下記ブログを参考にしました。
Pythonのインストール方法[Windows]
Windowsはpathを通すのが面倒だったりするんですが、チェックを忘れずに入れておけば問題なく動くようになりました。
続いて、seleniumをインストールします。
これは、上記ブログ「Pythonのインストール方法[Windows]」にも記載してありますが、コマンドプロンプトで pip install ライブラリ名 と入力すればインストールできます。
下記を入力してインストール完了です。
pip install selenium
▲ 目次に戻る
chromeドライバ
chromeドライバを入れます。
https://sites.google.com/a/chromium.org/chromedriver/downloadsからダウンロードします。
Latest Release: ChromeDriver 2.38 のChromeDriver 2.38をクリックします。
OSによって使えるchromeドライバのリストが表示されます。
私はwindows10なのでchromedriver_win32.zipをダウンロードしました。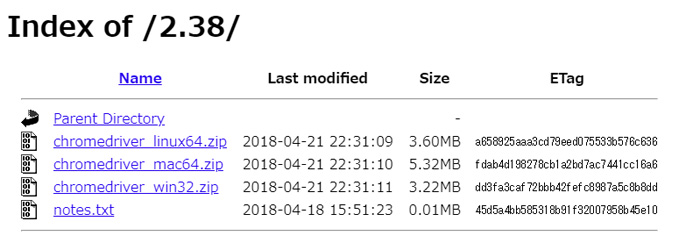
解凍すると、「chromedriver.exe」ファイルがあるので、任意の位置に格納します。
私は「c:/chromedriver_win32/」に格納しました。
格納先を後ほどpythonプログラムで指定します。
▲ 目次に戻る
各ファイルの説明
自動キャプチャに必要な各ファイルを作成していきます。
list_dic.csv – キャプチャしたいページリスト
キャプチャしたいリストをcsv形式で作成します。
csvを辞書型で読み込みたいので、1行目は項目名を記述します。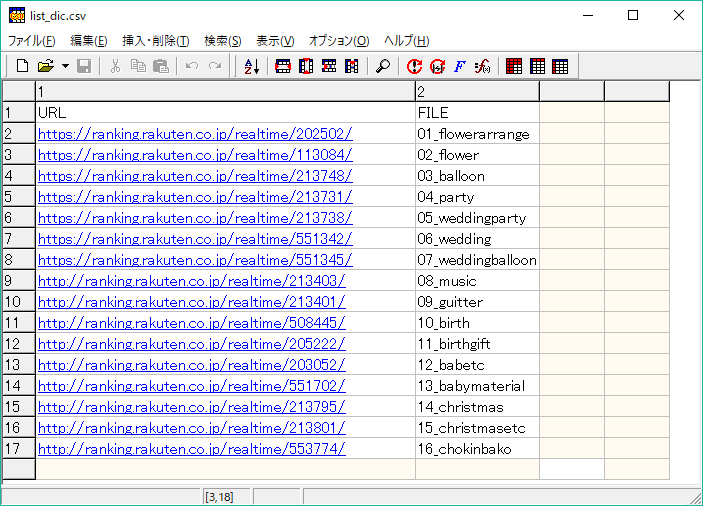
項目名は、pythonプログラムで指定します。
rakutenRank.py – pythonで実行するプログラム本体
import time
from datetime import datetime
import csv
import os
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import sys
#パラメータ取得
args = sys.argv
argc = len(args)
options = webdriver.ChromeOptions()
# 必須
options.add_argument('--headless')
options.add_argument('--disable-gpu')
# エラーの許容
options.add_argument('--ignore-certificate-errors')
options.add_argument('--allow-running-insecure-content')
options.add_argument('--disable-web-security')
# headlessでは不要そうな機能
options.add_argument('--disable-desktop-notifications')
options.add_argument("--disable-extensions")
# UA
options.add_argument('--user-agent=hogehoge')
# 言語
options.add_argument('--lang=ja')
# プラウザ起動(Chrome)
options.add_argument("--window-size=990, 1036")
driver = webdriver.Chrome(chrome_options=options,executable_path="c:/chromedriver_win32/chromedriver.exe")
#csvファイル読み込み
if argc != 2:
csv_file = open("./list_dic.csv", "r", encoding="shift_jis", errors="", newline="" )
else:
if args[1] == "dayly":
csv_file = open("./list_day_dic.csv", "r", encoding="shift_jis", errors="", newline="" )
f = csv.DictReader(csv_file, delimiter=",", doublequote=True, lineterminator="\r\n", quotechar='"', skipinitialspace=True)
folder = datetime.now().strftime("%Y%m%d-%H%M%S-pc") + "/"
os.mkdir(folder)
# リストからURLをひとつづつ処理
for row in f:
#1行目の項目名を指定
TITLE = row['FILE']
URL = row['URL']
# ドメインの一部をファイル名として設定
file_name = TITLE + ".png"
# URLを開く
driver.get(URL)
# ウィンドウサイズとズームを設定
driver.set_window_size(990, 1036)
driver.execute_script("document.body.style.zoom='100%'")
# 読み込み待機時間
time.sleep(2)
# imagesフォルダにスクリーンショットを保存
driver.save_screenshot("./" + folder + file_name)
# プラウザを閉じる
driver.quit()
rakutenRank.bat – タスクスケジューラで指定するコマンド
デスクトップにtestフォルダを作成して必要なファイルを保存しておきました。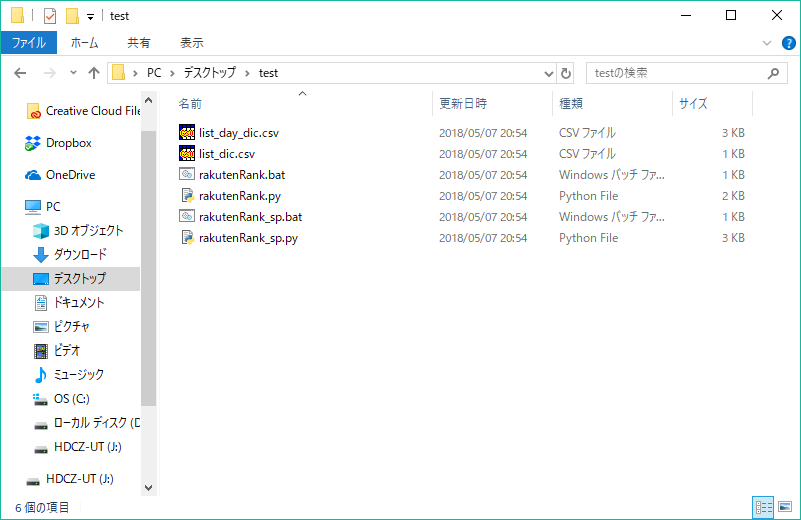
rakutenRank.batというファイル内には下記コマンドを記述しています。
cd C:\Users\ユーザー名\Desktop\test
python rakutenRank.py
exit
pythonプログラム本体はパラメータ指定で読み込むページリストファイルを変えるよう作りました。
| list_dic.csv | リアルタイムランキングで取得したいURLリスト | パラメータ不要 |
| list_day_dic.csv | デイリーランキングで取得したいリスト | パラメータ必要 |
リアルタイムランキングは上記コマンドで起動させ、デイリーランキングは下記コマンドで実行可能です。
cd C:\Users\ユーザー名\Desktop\test
python rakutenRank.py dayly
exit
▲ 目次に戻る
タスクスケジューラ(cronみたいなもの)を設定
Windowsでは、タスクスケジューラを使用します。
Cortana(コルタナ)の検索窓に[タスク]と入力して、見つかった[タスク スケジューラ]をクリックします。
[タスクスケジューラ ライブラリ]を右クリック→[タスクの作成]をクリックします。
[全般]タブの名前は任意名を記載します。
ユーザーログオンしていないときも動いてほしかったので、[ユーザーがログオンしているかどうかにかかわらず実行する]を選択しました。
[トリガー]タブに詳細の日時を記載します。楽天のリアルタイムランキングは15分おきに更新されるので、繰り返し間隔を[15分間]に設定します。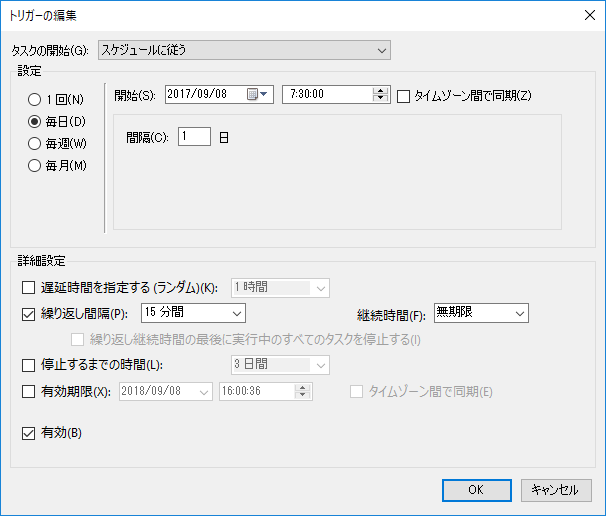
[操作]タブにrakutenRank.batを指定します。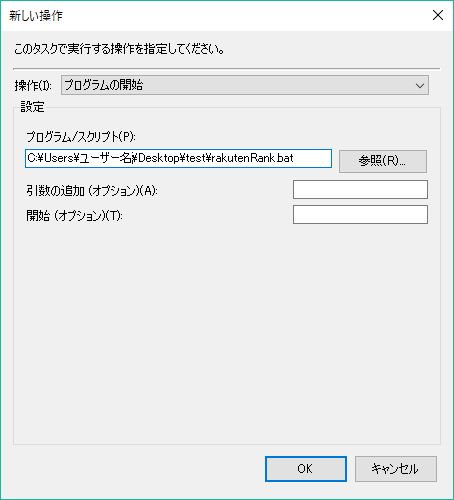
これで15分おきに楽天ランキングのキャプチャを取ることに成功しました。
Pythonで自動化はとても便利です。他にもいろいろと自動化をして便利になりたい方、Pythonの勉強をしたい方は、無料で入門講座を開いているスクールがあります。
▲ 目次に戻る