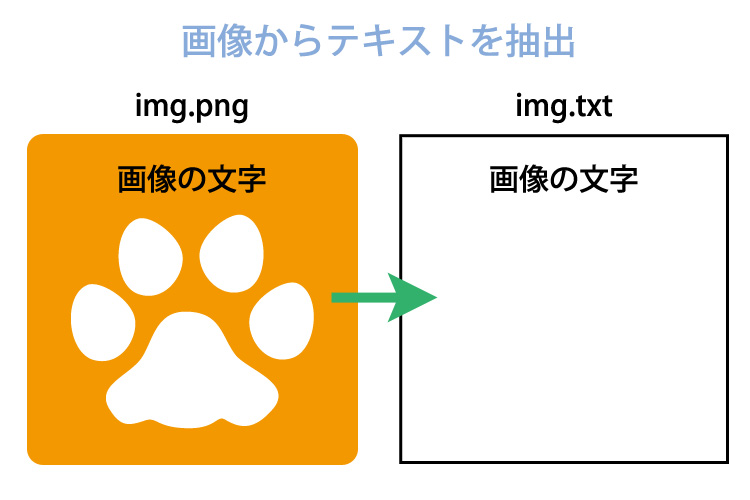
画像からテキストを抽出したいなと思い、指定URLの画像を全て保存し、画像から文字抽出するプログラムを作成しました。
pythonを使用して作成しました。
PythonでOCRを参考にしました。
pythonと必要なライブラリなどのインストール
Windowsしか手元にないので、Windowsのみの方法を記述してきます。
python
pythonのインストールは下記ブログを参考にしました。
Pythonのインストール方法[Windows]
Windowsはpathを通すのが面倒だったりするんですが、チェックを忘れずに入れておけば問題なく動くようになりました。
tesseract
OCRツールであるtesseractを入れます。
https://github.com/UB-Mannheim/tesseract/wikiにアクセスします。
使用しているパソコンのbitに合わせてダウンロードします。
私の場合は64bitをダウンロードしました。
ダウンロードしたexeファイルを実行してインストールします。
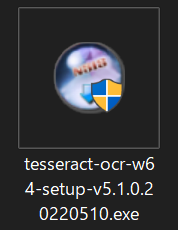
windowsから警告メッセージが表示されますが、「実行」をクリックします。
Install Languageと表示されますが、ここで日本語はないのでEnglishのまま「OK」をクリックします。
インストールはデフォルト設定のまま「Next」ボタンをクリックしていきます。
「Additional script data (download)」のプラスボタンをクリックし、「Japanese script」「Japanese vertical script」にチェックを入れます。
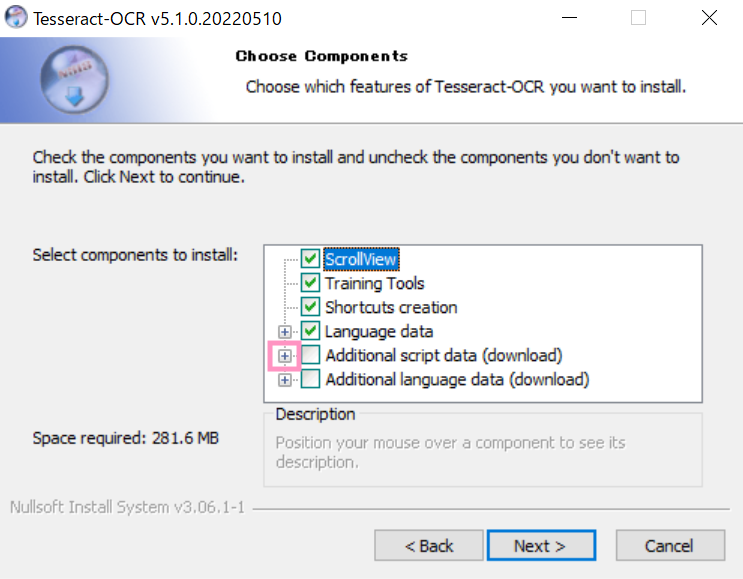
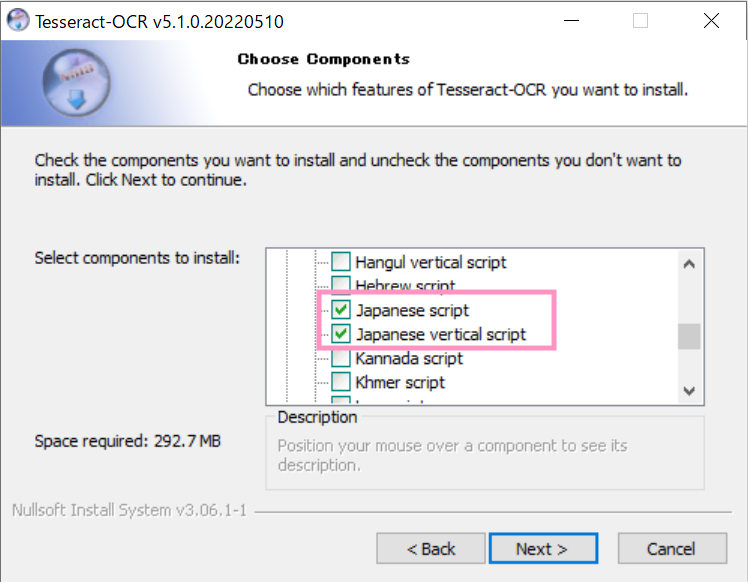
「Additional language data (download)」のプラスボタンをクリックし、「Javanese」「Japanese」「Japanese (vertical)」にチェックを入れます。
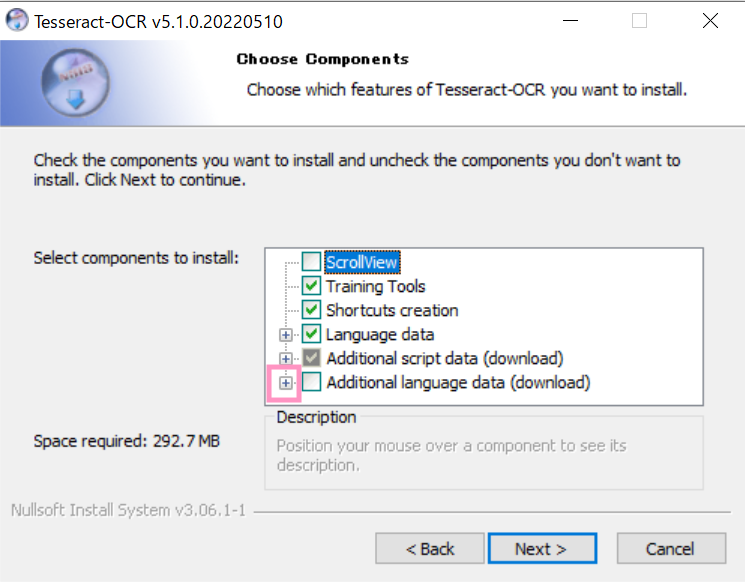
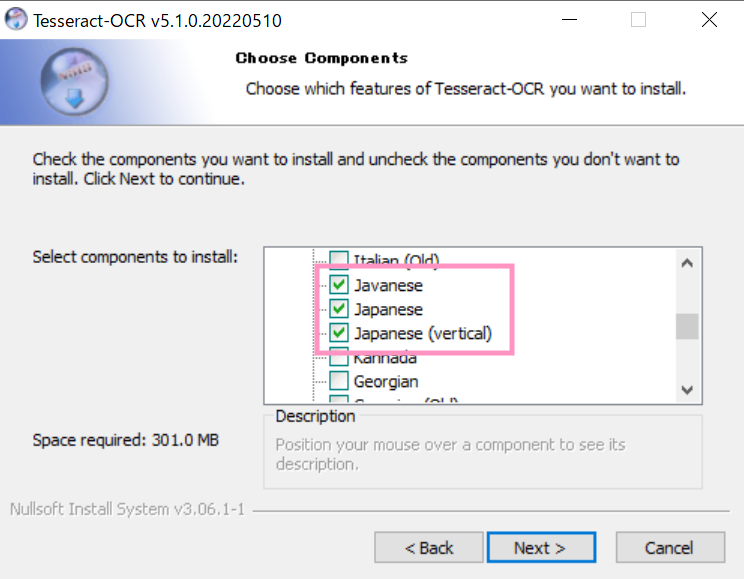
インストール後、”C:\Program Files\Tesseract-OCR”をPathに追加します。
環境変数設定画面を開きます。
開き方は2通りあります。
・Cortana(コルタナ)の検索窓に[コントロールパネル]と入力して、[システムとセキュリティ]→[システム]→[システムの詳細設定]をクリックする。
・[windowsキー+r→sysdm.cplと入力]→[詳細設定タブ]→[環境変数]
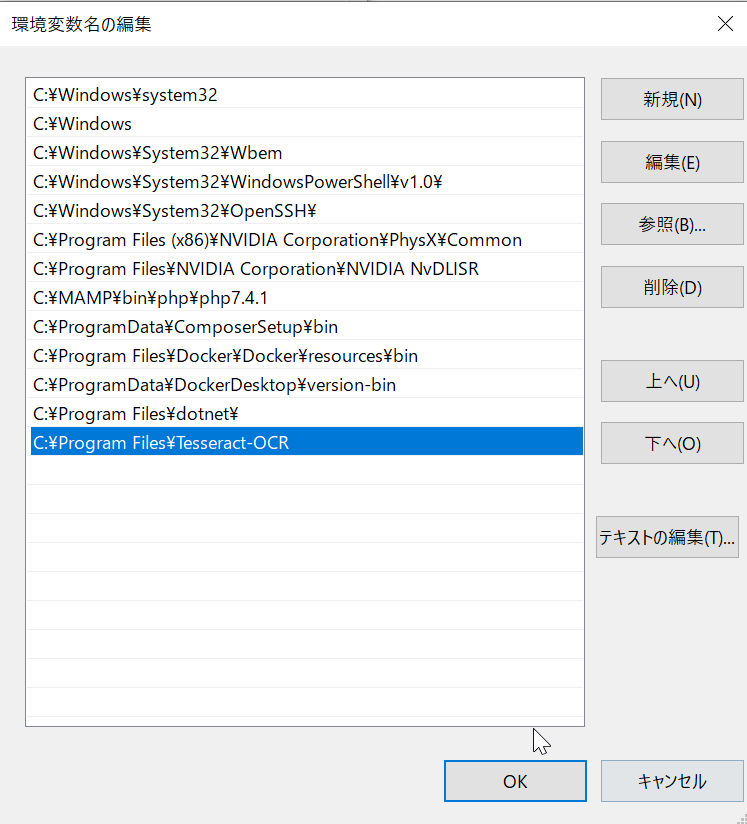
システム環境変数内にある[Path]を選択した状態で[編集]をクリックします。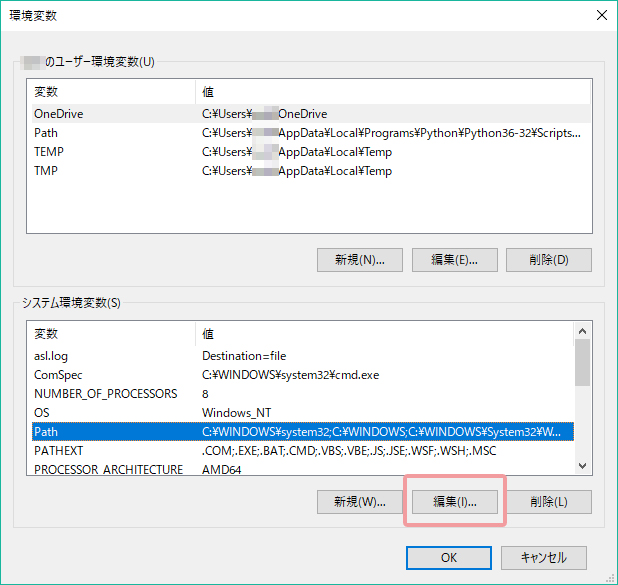
新規で下記を追加します。
C:\Program Files\Tesseract-OCR
インストール時に「Additional language data (download)」の「Japanise」のチェックを入れ忘れた場合は、日本語の文字解読ができるようにhttps://tesseract-ocr.github.io/tessdoc/Data-Filesからjpnをダウンロードします。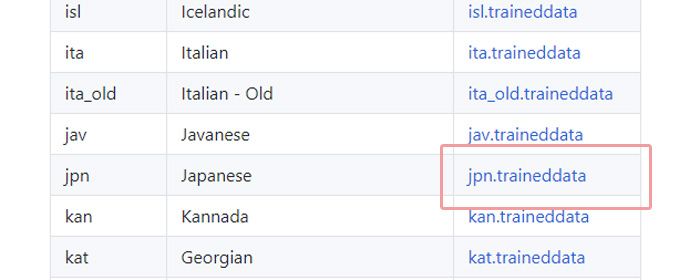
ダウンロードしたjpn.traineddataファイルを C:\Program Files\Tesseract-OCR\tessdata\ に格納します。
pythonのライブラリ
今回のプログラムで必要なpythonのライブラリをインストールします。
コマンドプロンプトで下記を実行してください。
pyocr
pip install pyocr
requests
pip install requests
beautifulsoup4
pip install beautifulsoup4
lxml
pip install lxml
▲ 目次に戻る
pythonで実行するプログラム本体
imgCollect.pyというファイル名で作成しました。
# パラメータ:フォルダ名 URL
import sys,os
import requests # urlを読み込むためrequestsをインポート
from bs4 import BeautifulSoup # htmlを読み込むためBeautifulSoupをインポート
from PIL import Image
import pyocr
import pyocr.builders
#パラメータ取得
args = sys.argv
URL = args[2] # URL入力
images = [] # 画像リストの配列
soup = BeautifulSoup(requests.get(URL).content,'lxml') # bsでURL内を解析
for link in soup.find_all("img"): # imgタグを取得しlinkに格納
if link.get("src").endswith(".jpg"): # imgタグ内の.jpgであるsrcタグを取得
images.append(link.get("src")) # imagesリストに格納・相対パスの場合は各サイトごとに微調整必要
elif link.get("src").endswith(".png"): # imgタグ内の.pngであるsrcタグを取得
images.append(link.get("src")) # imagesリストに格納・相対パスの場合は各サイトごとに微調整必要
#フォルダ作成
folder = args[1] + "/"
os.mkdir(folder)
file_name = [] # 画像リストの配列
for target in images: # imagesからtargetに入れる
re = requests.get(target)
with open(folder + target.split('/')[-1], 'wb') as f: # imgフォルダに格納
file_name.append(target.split('/')[-1])
f.write(re.content) # .contentにて画像データとして書き込む
pyocr.tesseract.TESSERACT_CMD = r'C:\Program Files\Tesseract-OCR\tesseract.exe' # OCRツールがみつからないエラー回避
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
langs = tool.get_available_languages()
print("Available languages: %s" % ", ".join(langs))
for imgFile in file_name: # file_nameからimgFileに入れる
txt = tool.image_to_string(
Image.open(folder + imgFile),
lang='jpn',
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
#print(txt)
name, ext = os.path.splitext(imgFile)
textfile = open(folder + name +'.txt', 'w')
textfile.write(txt.replace(' ', ''))
print("ok") # 確認
▲ 目次に戻る
実行コマンド
コマンドプロンプトからpythonを実行します。
cd の後のフォルダは、pythonプログラム本体「imgCollect.py」を格納しているフォルダを指定します。
python imgCollect.py フォルダ名 画像解読したいURL を指定します。
cd C:\Users\ユーザー名\Desktop\test
python imgCollect.py img https://retrobanner.net/
実行できましたが、小さい文字は認識できませんでした。
4バージョンの頃に比べるとだいぶ解読してくれるようになりました。
▲ 目次に戻る

